Tracking of Lagrangian River Floating Sensor using UAV based on Reinforcement Learning
Introduction:
A novel method of Reinforcement Learning, Deep Deterministic Policy Gradient(DDPG) is used to tackle the problem of landing an autonomous drone on a moving platform with the use just simple data i.e, GPS coordinates and imu data of drone and the base. Many methods have been emloyed before to tackle these kind of problems making use of raw pixels which need a lot of computation power to train and also less accurate. In our work we have just used low level control variables which made the training both less computative and more accurate.
Methodology:
A gazebo simulation (nearly equivalent to real world) is made to simulate UAV and moving platform where the training is performed. The communication between Gazebo and RL algorithm is established using ROS. Both the UAV and the platform are mounted with GPS and odometry sensors whose data is given as input to train the RL model. A QR code is pasted on the top of platform surface which is used to tackle the errors in the GPS data and the gimbal angle of UAV camera is controlled to get the QR code into centre of frame irrespective of position of drone.
Environment:
A gazebo environment is simulated for the sake of training.
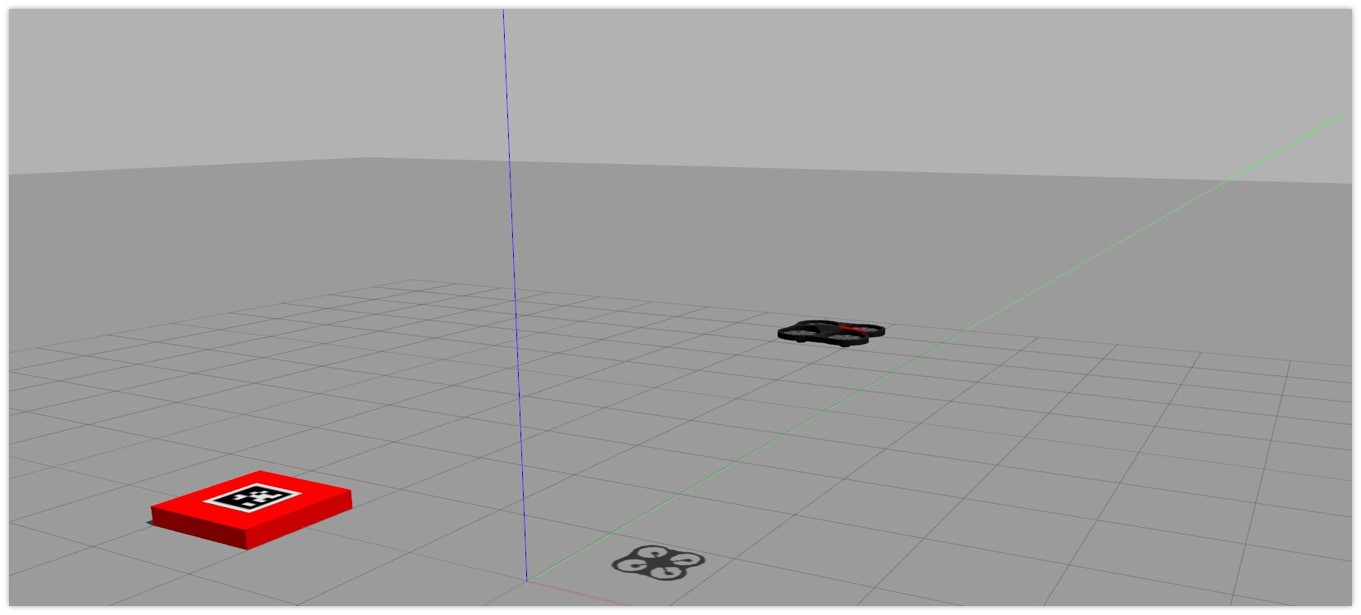
Gimbal:
This is the view of UAV camera and we can see that the MP is always in the frame disregard to position of UAV. Click the below image to see the working of gimbal:

Reinforcement Learning:
In recent years many RL algorithms like DQN, DDPG, A3C, NAF,TRPO, PPO have been developed. In our case Deep Deterministic policy Gradient(DDGP) is chosen since the UAV works on continuous action spaces. DDPG works on a actor-critic principle where actor generates the desired actions from state inputs and critic generates an error signal called Temporal Difference. Both actor and critic can be represented by using Deep Neural Networks. We considered a state space of dimension six and an action space of dimension two. The six states are: Differences in positions of UAV and MP in x, y, z dimensions. Difference of velocities of in x, y directions. Binary value that indicates the UAV has reached the desired position. The two actions are velocity inputs given to UAV in x, y directions. We consider the velocity of UAV in z direction to be a constant negative value to maintain stability and also reduce computation.
Final Results:
Click below to watch the UAV tracking drone:

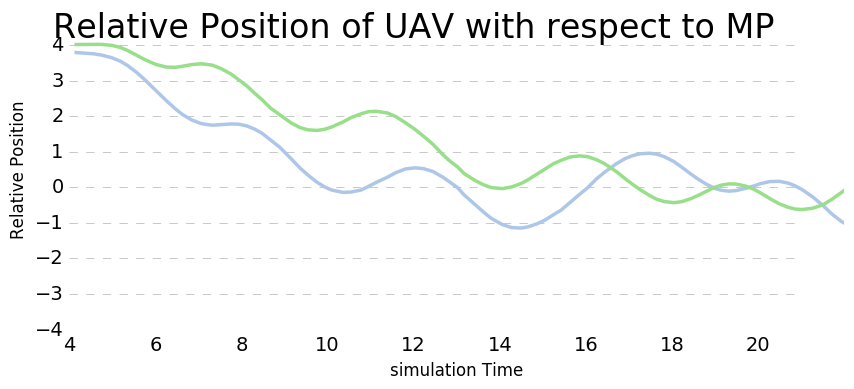
The plot of relative positions UAV with resepect to Moving Platform over time